union all =(축약)=> grouping sets =(축약)=> rollup / cube
1. group by grouping sets();
emp 테이블의 gender 을 그룹핑 + emp 테이블의 ()을 그룹핑 = 두개의 group by 결과물은 union all로 한 것과 같다.
// grouping set을 사용하는 경우
select gender, count(*) from emp group by grouping set (gender, ());
// union all을 사용하는 경우
select gender, count(*) from emp group by gender
union all
select '전체', count(*) from emp;
group by 절 내 실행 순서는 (1)group by (속성1) (2)group by (속성2) 후 (1) + (2) 을 더한다.
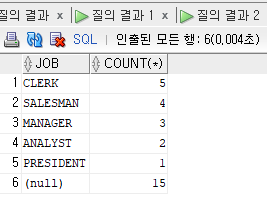
select job, count(*)
from emp
group by grouping sets(job, ());
2. grouping set을 짧게 해주는 함수
Rollup()
select gender, count(*)
from emp
group by rollup(gender);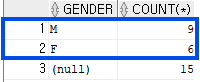
group by grouping sets (gender, ()) 의 축약
select gender, deptno, job, count(*)
from emp
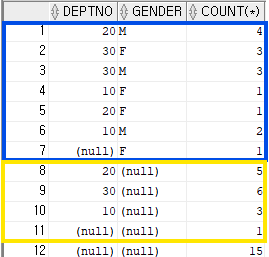
group by rollup(gender, deptno, job);group by grouping sets ( (gender, deptno, job), (gender, deptno), (gender), () ) , 의 축약
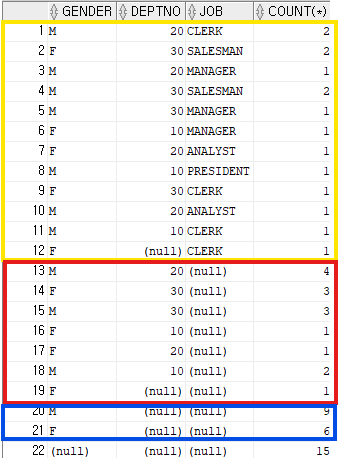
매개값을 뒤에서 부터 하나씩 빼면서 그룹핑 하면된다.
노란색 = gender별 deptno별 job
빨간색 = gender별 deptno
파란색 = gender
22번행 = ()
cube() : 매개 값의 모든 경우 수의 통계치를 group by를 한다.
- > 모든 grouping sets의 모든 경우의 수를 출력한다. (그러므로 매개값이 한개라면 cube와 rollup의 결과물은 같다.)
모든 경우의 수 = 중복이 없어야한다 = '정렬-해시-정렬'을 한다 = rollup 보다는 cube가 느림
간단한 결과를 출력하기 위해서는 cube를 사용하지 않는다.
select gender, deptno, count(*)
from emp
group by cube(gender, deptno);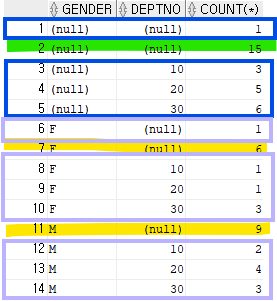
4. rollup(), cube()가 사용된 select절에 사용 : grouping()
※ emp 테이블

select deptno, count(*)
from emp
group by rollup(deptno);
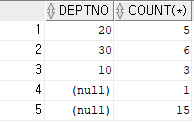
Ace의 deptno 가 null이므로, 총합을 나타내는 null과 구분 필요 -> grouping()을 이용
select deptno, count(*), grouping(deptno)
from emp
group by rollup(deptno);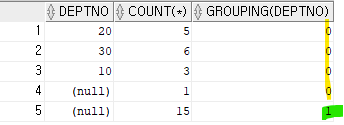
0 = > deptno로 그룹핑 되었다.
1 = > deptno로 그룹핑이 되지 않았다
이를 이용해서 Ace의 deptno null값을 다른 값으로 치환할 수 있다.
select (case when grouping(deptno) = 0 then deptno else 0 end) as 부서번호, count(*), grouping(deptno)
from emp
group by rollup(deptno);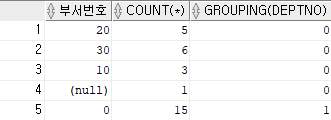
정리
(1) grouping sets -> deptno 계산셋, gender 계산셋을 잇는다. (union all 와 결과 같음)
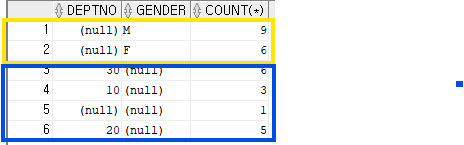
(2) rollup : dept+gender 계산셋 + dept 계산셋 + () 계산셋 (뒤에 있는 속성값 하나씩 짜르면서 이으므로, 모든 경우의 수가 나오진 않는다)
(3) cube : dpet+gender 계산셋 + dept 계산셋 + gender 계산셋 + () 계산셋 (모든 속성 조합 경우의 수 기준으로 계산셋 출력)

※ Rollup 함수는 인수의 순서가 달라지면, 결과가 달라지는 반면, grouping sets와 cube 함수는 변하지 않는다.
§ 윈도우 함수 사용 옵션
UNBOUNDEED PRECEDING 위쪽 끝 행
UNBOUNDED FOLLOWING 아래쪽 끝 행
CURRENT ROW 현재 행
n PRECEDING 현재 행에서 위로 n만큼 이동
n FOLLOWING 현재 행에서 아래로 n 만큼 이동
'SQL' 카테고리의 다른 글
| 프로그래머스 SQL - 상위 퍼센트 대로 나누기 / percent_rank() (0) | 2025.03.27 |
|---|---|
| [DB]NULL값 허용과 관계테이블 (0) | 2024.11.20 |
| SQL 깜지 (0) | 2024.10.25 |
| [Oracle] 비율함수 (0) | 2024.10.25 |
| [oracle sql] 의사 컬럼, 분석 함수, 계층 쿼리 (0) | 2024.10.22 |